According to Lin et al. (2025), AI safety and AI security differ in the following way:
AI Safety: risks from accidental or unintended behaviors.
AI Security: risks from intentional or adversarial actions by malicious actors.
Main documents on AI safety and AI security¶
The International AI Safety Report is the world’s first comprehensive review of the latest science on the capabilities and risks of general-purpose AI systems:
OWASP AI Exchange is a practical resource on AI security and privacy (>200 pages)
Federal Office for Information Security issues studies, catalogues, and checklists on AI: https://
www .bsi .bund .de /EN /Themen /Unternehmen -und -Organisationen /Informationen -und -Empfehlungen /Kuenstliche -Intelligenz /kuenstliche -intelligenz _node .html
AI Safety risks from the AI Safety report¶
Selected risks from the AI safety report relevant in research context¶
Risks from malicious use
Harm to individuals through fake content. AI-generated fake content can be used to manipulate governance processes, sabotage collaborations, or personally target researchers and undermine trust in science.
Manipulation of public opinion. AI-generated fake content and narrative manipulation can directly target researchers, research projects, research ideas, and public trust in science.
Cyber offence. AI-assisted cyber attacks may affect research infrastructures, collaborations, and sensitive scientific outputs.
Biological and chemical attacks.
Risks from malfunctions
Reliability issues. This can lead violations of research ethics, research integrity, and research governance due to irresponsible use of AI systems having reliability issues.
Bias. Biased data, models, and AI systems can lead to discriminatory or misleading results violating research ethics principles. Researchers have an ethical duty to identify, mitigate, and transparently report bias.
Systemic risks
Risks to the environment. Key ethical question for research projects: Is the environmental cost of using an AI system justified by the expected scientific and societal benefit?
Risks to privacy. This can lead to violations of research ethics, research integrity, and research governance.
Risks of copyright infringement. This can lead to violations of research ethics, research integrity, and research governance.
Impact of open-weight general-purpose AI models on AI risks.
Risks from open-weight general-purpose AI models on AI risks¶
The AI safety report has the following points:
Risks posed by open-weight models are largely related to enabling malicious or misguided use, because general-purpose AI models are dual-use:
Safeguards against misuse are easier to remove for open models
Model vulnerabilities found in open models can also expose vulnerabilities in closed models
Once model weights are available for public download, there is no way back
There are risk mitigation approaches for open-weight models throughout the AI lifecycle. The most robust risk mitigation strategies will aim to address potential issues at every stage from data collection to post-release measures such as vulnerability disclosure.
From the other side:
Security by obscurity is not recommended by NIST: “System security should not depend on the secrecy of the implementation or its components.”
The Kerckhoffs’s principle: “A system should be secure, even if everything about the system is public knowledge.”
“In modern computer security, a hard-fought broad-based consensus has been established: Despite the intuitive idea that hiding a system should protect it, transparency is often more beneficial for protection. The consensus on this general principle is broad, though perspectives on how to implement the principle in specific contexts can be more varied.” Hall et al. (2025)
In research: Open Science + Safety + Security = As open as possible, as closed as necessary.
AI Security Exchange¶
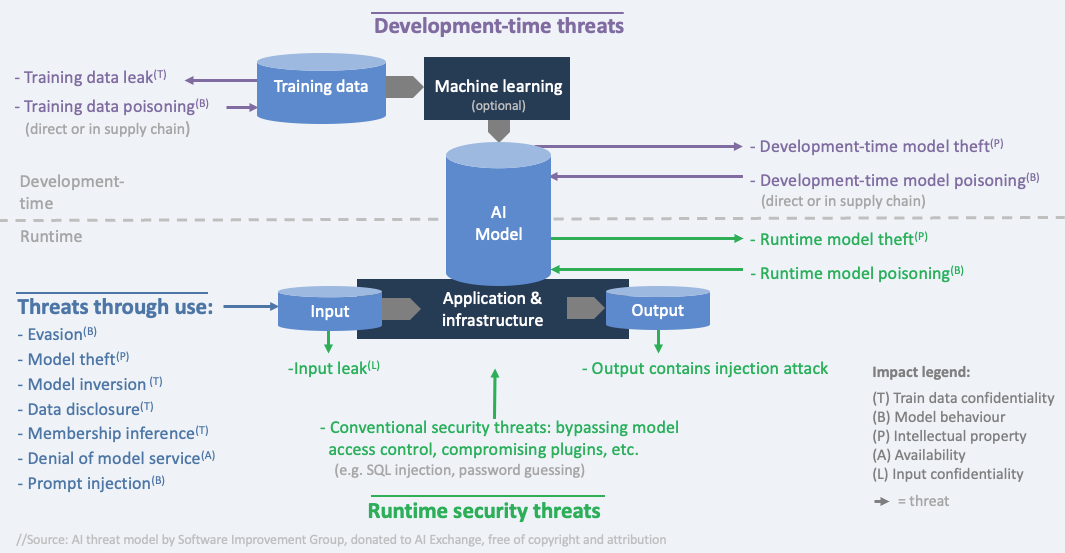
Threat model: Types of threats¶
Three types of threats (https://
threats during development-time: when data is obtained and prepared, and the model is trained/obtained. Example: data poisoning (injecting bad data into the training data)
threats through using the model: through inference; providing input and getting the output. Examples:
direct prompt injection (malicious prompt into the user interface),
indirect prompt injection (malicious prompt is embedded in external content) or
evasion (hidden malicious instructions via obfuscation, encoding, hidden text, and payload splitting)
other threats to the system during runtime: in operation - not through inference. Example: stealing model input
Threat model: Impacts¶
6 types of impacts that align with three types of attacker goals (disclose, deceive and disrupt):
disclose: hurt confidentiality of train/test data
disclose: hurt confidentiality of model Intellectual property (the model parameters or the process and data that led to them)
disclose: hurt confidentiality of input data
deceive: hurt integrity of model behaviour (the model is manipulated to behave in an unwanted way and consequentially, deceive users)
disrupt: hurt availability of the model (the model either doesn’t work or behaves in an unwanted way - not to deceive users but to disrupt normal operations)
disrupt/disclose: confidentiality, integrity, and availability of non AI-specific assets
Threats to agentic AI¶
Threats:
Hallucinations and prompt injections can change commands or even escalate privileges.
Leak of sensitive data due to the „lethal trifecta“:
Data: Control of the attacker of data that find its way into an LLM at some point in the session of a user that has the desired access, to perform indirect prompt injection
Access: Access of that LLM or connected agents to sensitive data
Send: The ability of that LLM or connected agents to initiate sending out data to the attacker
- Lin, Z., Sun, H., & Shroff, N. (2025). AI Safety vs. AI Security: Demystifying the Distinction and Boundaries. arXiv. 10.48550/ARXIV.2506.18932
- Hall, P., Mundahl, O., & Park, S. (2025). The Pitfalls of “Security by Obscurity” and What They Mean for Transparent AI. Proceedings of the AAAI Conference on Artificial Intelligence, 39(27), 28042–28051. 10.1609/aaai.v39i27.35022